Diving into the vibrant intersection of the Metaverse and Multimedia Information Retrieval (MMIR), we uncover a fascinating journey that’s shaping the future of Metaverse integration with MMIR. Imagine stepping into a universe where the boundaries between physical and digital realities blur, creating an immersive world teeming with multimedia content. This is the Metaverse, a collective virtual space, built on the pillars of augmented and virtual reality technologies.
At the heart of integrating these worlds lies the challenge of efficiently indexing, retrieving, and making sense of a deluge of multimedia content—ranging from images, videos, to 3D models and beyond. Enter the realm of Multimedia Information Retrieval (MMIR), a sophisticated field dedicated to the art and science of finding and organizing multimedia data.
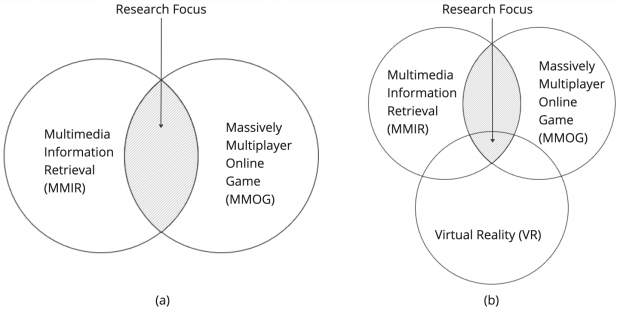
The research explored here, as my Ph.D. project, ventures into this nascent domain, proposing innovative frameworks for bridging the Metaverse with MMIR. Their work unveils two primary narratives: one, how we can leverage MMIR to navigate the vast expanses of the Metaverse, and two, how the Metaverse itself can generate new forms of multimedia for MMIR to organize and retrieve.
In the first scenario, imagine you’re an educator in the Metaverse, looking to build an interactive, virtual classroom. Through the integration of MMIR, you can seamlessly pull educational content—be it historical artifacts in 3D, immersive documentaries, or interactive simulations—right into your virtual space, enriching the learning experience like never before.
The second scenario flips the perspective, showcasing the Metaverse as a prolific generator of multimedia content. From virtual tours and events to user-generated content and beyond, every action and interaction within the Metaverse creates data ripe for MMIR’s picking. This opens up a new frontier for content creators and researchers alike, offering fresh avenues for creativity, analytics, and even virtual heritage preservation.
Navigating these possibilities, the research present sophisticated models and architectures, such as the Generic MMIR Integration Architecture for Metaverse Playout (GMIA4MP) and the Process Framework for Metaverse Recordings (PFMR). These frameworks lay the groundwork for seamless interaction between the Metaverse and MMIR systems, ensuring content is not only accessible but meaningful and contextual.
To bring these concepts to life, let’s visualize a diagram illustrating the flow from multimedia creation in the Metaverse, through its processing by MMIR systems, to its ultimate retrieval and utilization by end-users. This visualization underscores the cyclical nature of creation and discovery in this integrated ecosystem.
In essence, this research lights the path toward a future where the Metaverse and MMIR coalesce, creating a symbiotic relationship that enhances how we create, discover, and interact with multimedia content. It’s a journey not just of technological innovation, but of reimagining the very fabric of our digital experiences.
Let’s create an image to encapsulate this vibrant future: Picture a vast, sprawling virtual landscape, brimming with diverse multimedia content—3D models, videos, images, and interactive elements. Within this digital realm, avatars of researchers, educators, and creators move and interact, bringing to life a dynamic ecosystem where the exchange of multimedia content is fluid, intuitive, and boundlessly creative. This visualization, rooted in the essence of the research, will capture the imagination, inviting readers to envision the endless possibilities at the intersection of the Metaverse and MMIR.